一、原理详解
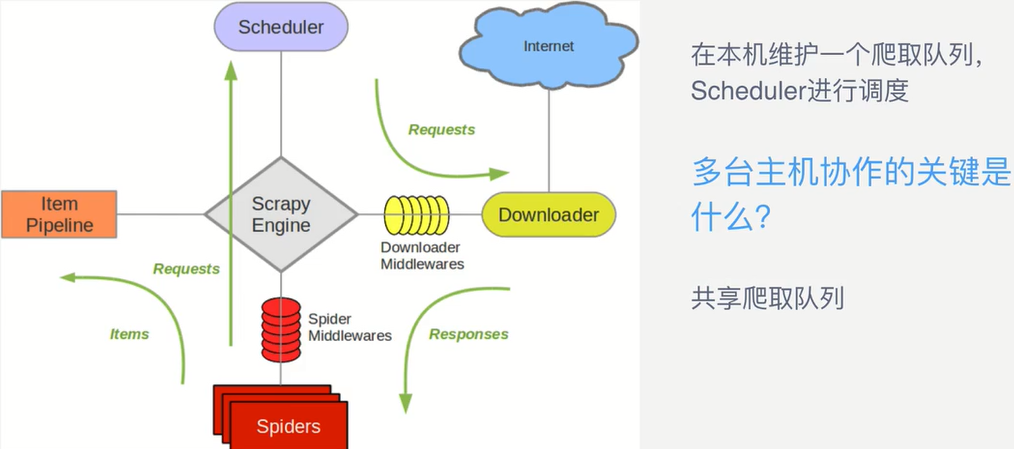
1、Scrapy单机架构
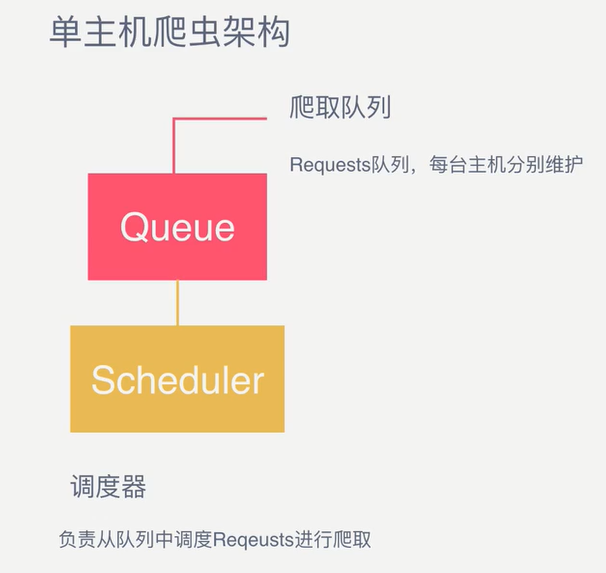
2、 单主机爬虫架构
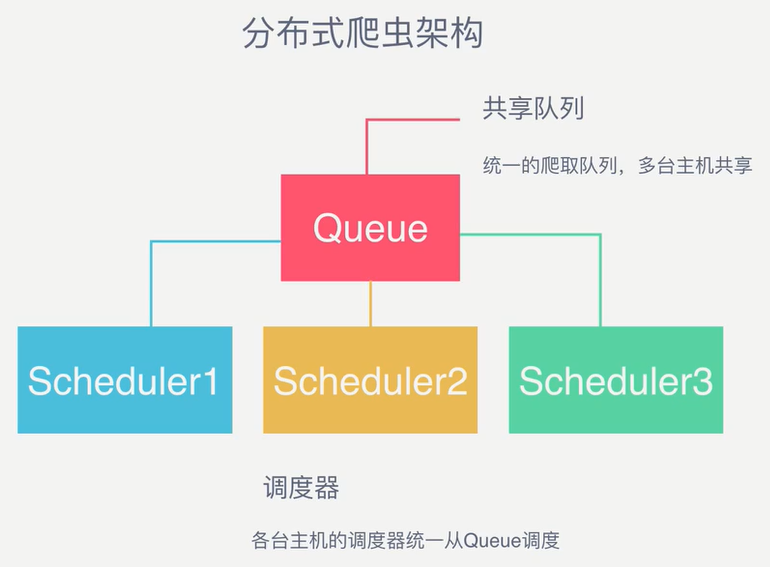
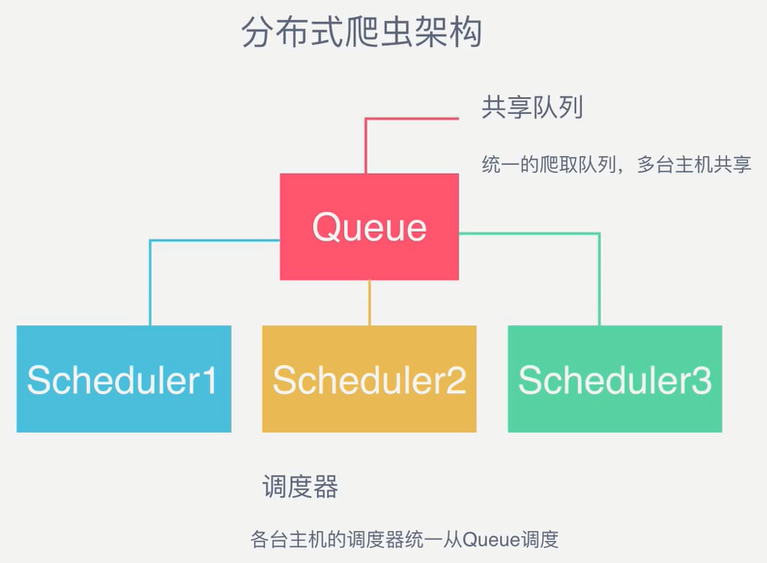
3、分布式爬虫架构
4、队列用什么维护?
Redis队列:
Redis,非关系型数据库,Key-Value形式存储,结构灵活。
是内存中的数据结构存储系统,处理速度快,性能好。
提供队列、集合等多种存储结构,⽅方便队列维护。
5、怎样来去重?
Redis集合:
Redis提供集合数据结构,在Redis集合中存储每个Request的指纹。
在向Request队列中加入Request前首先验证这个Request的指纹是否已经加入集合中。
如果已存在,则不添加Request到队列,如果不存在,则将Request添加入队列并将指纹加入集合。
6、怎样防⽌止中断?
启动判断:
在每台从机Scrapy启动时都会首先判断当前Redis Request队列是否为空。
如果不为空,则从队列中取得下一个Request执行爬取。
如果为空,则重新开始爬取,第一台从机执行爬取向队列中添加Request。
7、怎样实现该架构?
Scrapy-Redis:
Scrapy-Redis库实现了如上架构,改写了Scrapy的调度器,队列等组件。
利用它可以方便地实现Scrapy分布式架构。
github地址:https://github.com/rolando/scrapy-redis
安装pip install scrapy-redis
8、源码讲解
scrapy_resis/connection.py # 连接redis的基本的库
scrapy_resis/default.py # 一些默认的变量
scrapy_resis/dupefilter.py # 用来去重的一个机制
scrapy_resis/picklecompat.py # 和json的load和dump类似
scrapy_resis/pipelines.py # 管道,增加了集中存储到resids
scrapy_resis/queue.py # 队列
scrapy_resis/scheduler.py # 调度器
scrapy_resis/spiders.py # 定义了某些spider
scrapy_resis/unils.py # 一些工具库
持续更新…
最后更新: 2018年08月16日 17:51
原始链接: http://pythonfood.github.io/2018/07/05/Scrapy分布式原理及Scrapy-Redis源码解析/
